总览图
04 索引(上)
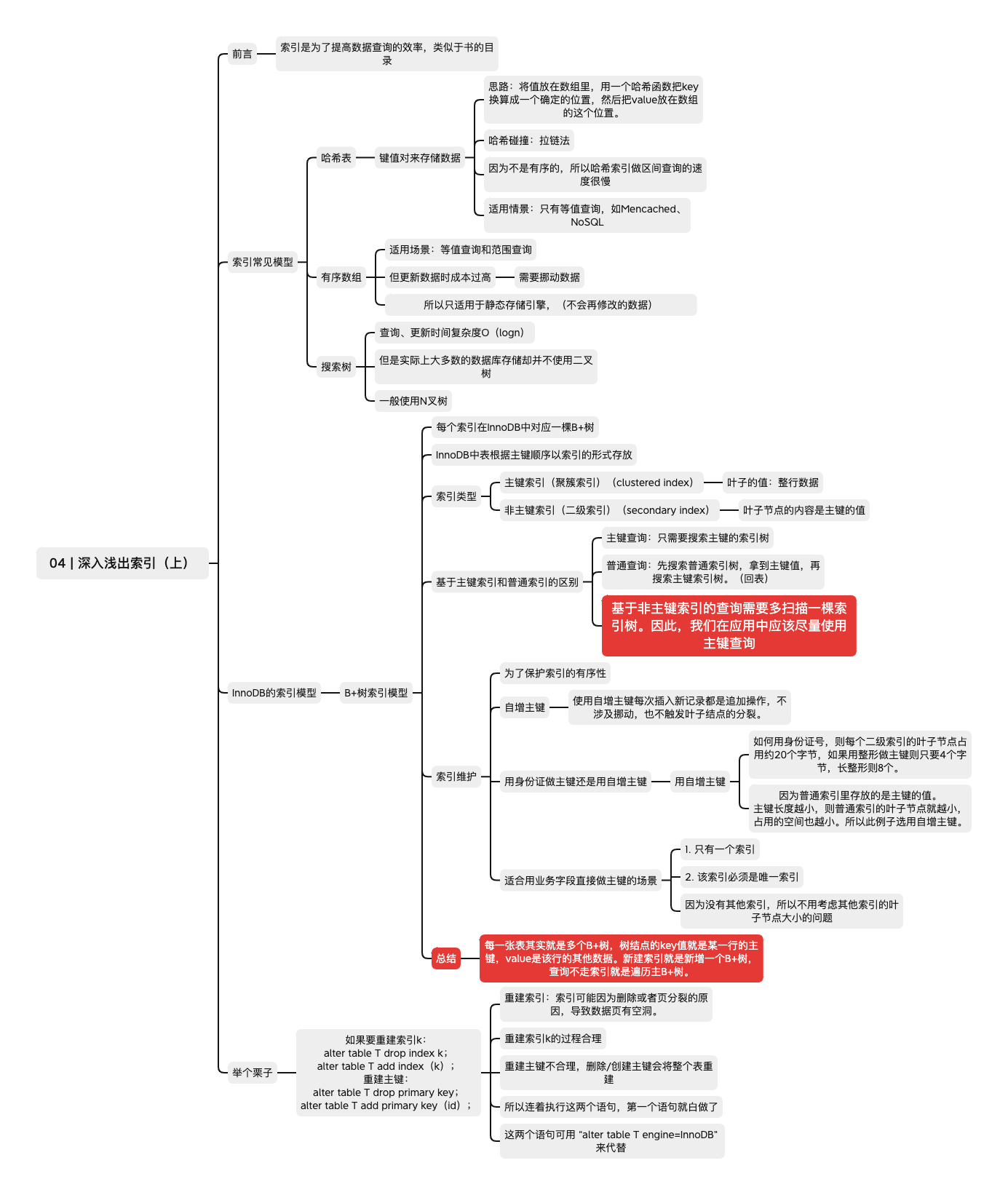
索引是为了提高数据查询的效率,类似于书的目录
索引常见模型
-
哈希表
键值对来存储数据
- 思路:将值放在数组里,用一个哈希函数把key换算成一个确定的位置,然后把value放在数组的这个位置。
- 哈希碰撞:拉链法
- 因为不是有序的,所以哈希索引做区间查询的速度很慢
- 适用情景:只有等值查询,如Mencached、NoSQL
-
有序数组
-
适用场景:等值查询和范围查询
-
但更新数据时成本过高
- 需要挪动数据
-
所以只适用于静态存储引擎,(不会再修改的数据)
-
-
搜索树
- 查询、更新时间复杂度O(logn)
- 但是实际上大多数的数据库存储却并不使用二叉树
- 一般使用N叉树
InnoDB的索引模型
-
B+树索引模型
- 每个索引在InnoDB中对应一棵B+树
InnoDB中表根据主键顺序以索引的形式存放
索引类型
主键索引(聚簇索引)(clustered index)
叶子节点的值:整行数据
非主键索引(二级索引)(secondary index)
叶子节点的内容是主键的值
基于主键索引和普通索引的区别
-
主键查询:
select * from T where ID=500
只需要搜索主键的索引树
-
select * from T where k=5
普通查询:先搜索普通索引树,拿到主键值,再搜索主键索引树。(回表)
基于非主键索引的查询需要多扫描一棵索引树,也就是需要回表操作。因此,我们在应用中应该尽量使用主键查询
索引维护
为了保护索引的有序性
自增主键
使用自增主键每次插入新记录都是追加操作,不涉及挪动,也不触发叶子结点的分裂。
用身份证做主键还是用自增主键?
用自增主键
如果用身份证号,则每个二级索引的叶子节点占用约20个字节,如果用整形做主键则只要4个字节,长整形则8个。因为普通索引里存放的是主键的值。主键长度越小,则普通索引的叶子节点就越小,占用的空间也越小。所以此例子选用自增主键。
适合用业务字段直接做主键的场景
- 只有一个索引
- 该索引必须是唯一索引
因为没有其他索引,所以不用考虑其他索引的叶子节点大小的问题
总结
每一张表其实就是多个B+树,树结点的key值就是某一行的主键,value是该行的其他数据。新建索引就是新增一个B+树,查询不走索引就是遍历主B+树。
举个栗子
如果要重建索引k:
alter table T drop index k;
alter table T add index(k);
重建主键:
alter table T drop primary key;
alter table T add primary key(id);
重建索引:索引可能因为删除或者页分裂的原因,导致数据页有空洞。
重建索引k的过程合理重建主键不合理,删除/创建主键会将整个表重建
所以连着执行这两个语句,第一个语句就白做了
这两个语句可用 “alter table T engine=InnoDB” 来代替