本系列笔记学习MySQL 45讲,思维导图来源网络,侵删。
总览图
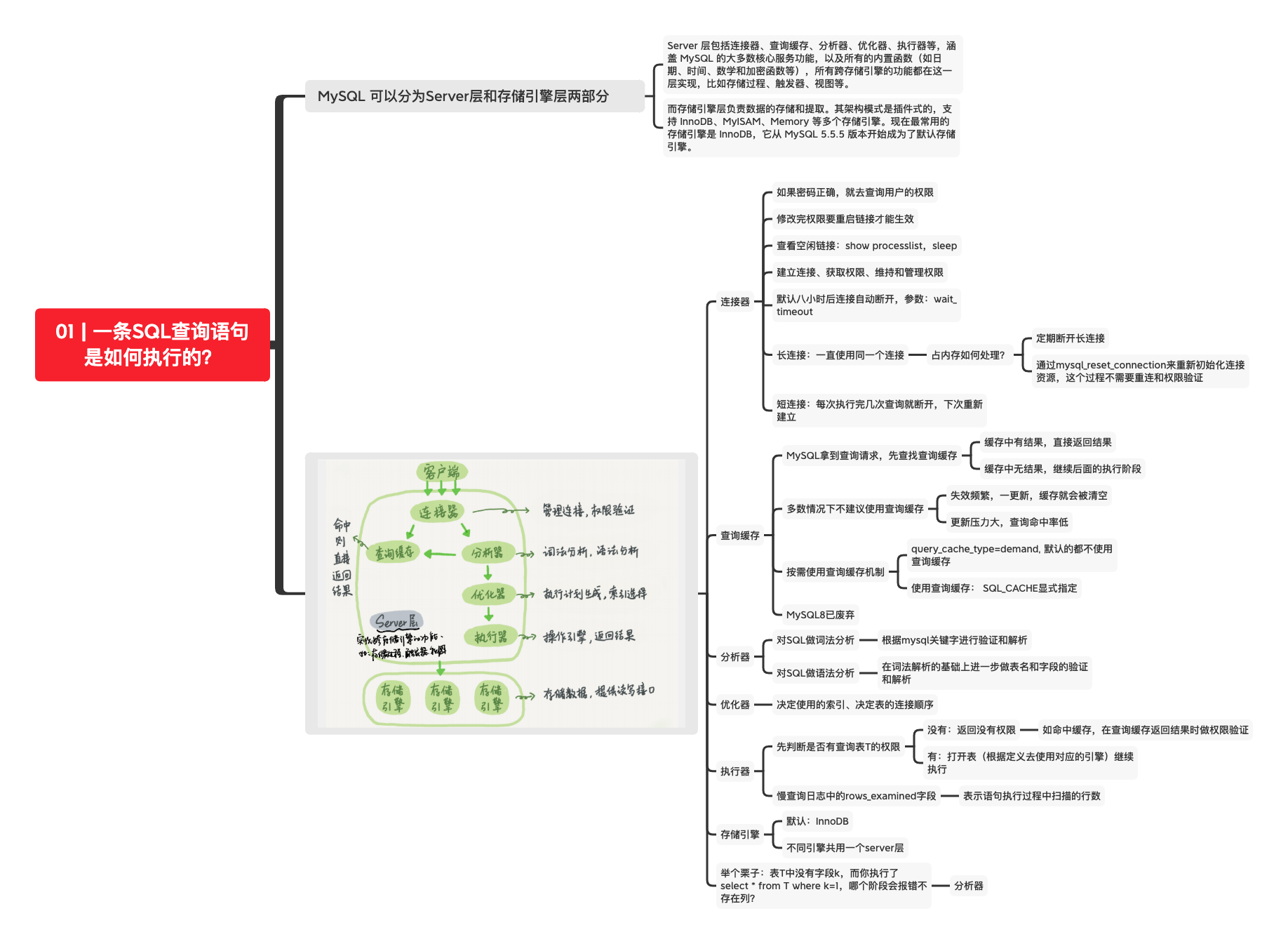
1.sql执行过程
先查询缓存
一般不建议使用查询缓存,因为一个表的更新会导致这个表的缓存结果失效,重复的建立缓存并不是高效的使用办法。除非这个表不会经常变动,如系统配置表
query_cache_type=demand, 默认的都不使用查询缓存
使用查询缓存: SQL_CACHE显式指定
没命中缓存会去执行语句
分析器做词法分析(分析每个字符串)、语法分析(判断是否满足语法)
分析器处理后会经过优化器处理
优化器的作用是选择使用哪种方案执行起来更为高效
执行器执行语句
先判断是否有权限执行
若有,则打开表继续执行
总览图
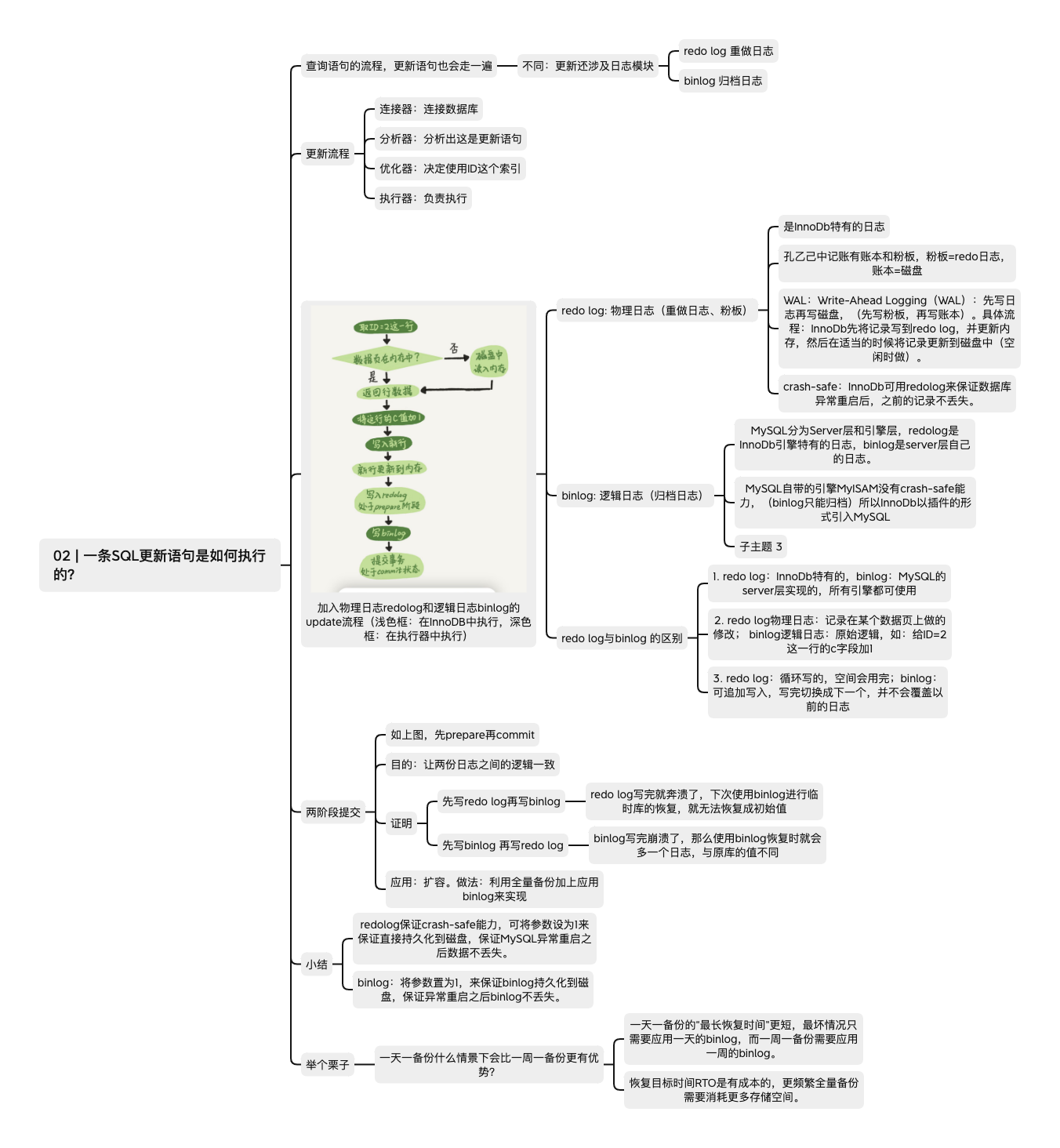
2. 更新语句执行过程
WAL 技术(Write-Ahead Logging)
先写日志,再写磁盘
重要的日志模块: redo log
redo log 是 InnoDB 引擎特有的日志
当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log(粉板)里面,并更新内存,这个时候更新就算完成了
重要的日志模块:binlog
Server 层也有自己的日志,称为 binlog(归档日志)
redo log 与 binlog 的不同
- redo log 是innodb特有的,而binlog是server层实现的,所以其他的存储引擎也可以用
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
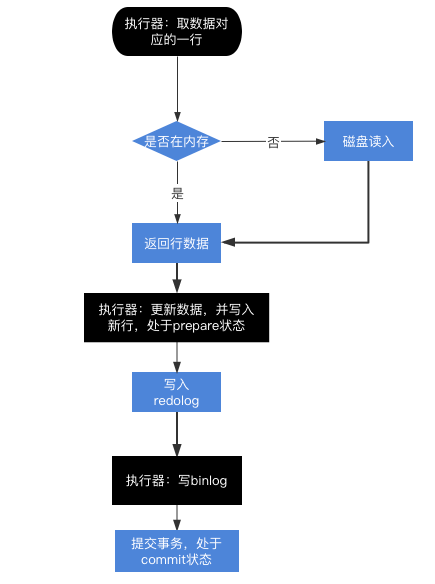
执行器找到要更新的数据
执行器找到要更新的数据后,若不在内存中,先读入内存,
然后将更新的数据先更新到内存,
写redo log, 进入 prepare状态,
执行器将 bin log 写入磁盘
提交事务,将 redolog 改成提交状态
更新完成
两阶段提交优点
因为是两阶段提交,redolog只是完成了prepare, 如果binlog失败,那么事务本身会回滚,库中的值不会修改。
如果不是两段式提交?
假设当前 ID=2 的行,字段 c 的值是 0,再假设执行 update 语句过程中在写完第一个日志后,第二个日志还没有写完期间发生了 crash,会出现什么情况呢?
update T set c=c+1 where ID=2;
- 先写 redo log 后写 binlog。假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。由于我们前面说过的,redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。
但是由于 binlog 没写完就 crash 了,这时候 binlog 里面就没有记录这个语句。因此,之后备份日志的时候,存起来的 binlog 里面就没有这条语句。然后你会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同。 - 先写 binlog 后写 redo log。如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。所以,在之后用 binlog 来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同。
翻译翻译:
先写redo log ,(1) 再写 bin log
如果(1)处发生故障,还没有写bin log。
系统恢复时,用 redolog 恢复,恢复之后的值是更新之后的值,但如果用bin log 恢复,会少一次更新。与更新之后的值不同
先写 bin log ,(1)再写 redo log
如果(1)处发生故障,bin log 已经写入了日志,但是 redo log 没有记录,数据还是旧值。
系统恢复时,以bin log 来恢复,因为已经写入了binlog , 值为新值,
会多出一个事务,这个事务是redo log 所没有操作的。
修订记录
2022-02-07 18:00:58