如果只想背八股,可以直接看最后总结部分
一致性分类
什么是一致性,简单的来说就是评判一个并发系统正确与否的标准。
分布式系统中的一致性从强到弱可以分为四种:
- 线性一致性 (Linearizability:Strong consistency or Atomic consistency)
- 顺序一致性(Sequential consistency)
- 因果一致性(Causal consistency)
- 最终一致性(Eventual consistency)
强一致性包括线性一致性和顺序一致性,其他的如因果一致性、最终一致都是弱一致性。
强一致性集群中,对任何一个节点发起请求都会得到相同的回复,但将产生相对高的延迟。而弱一致性具有更低的响应延迟,但可能会回复过期的数据,最终一致性即是经过一段时间后终会到达一致的弱一致性。
http://www.xuyasong.com/?p=1970
顺序一致性
如果可以找到一个所有 CPU 执行指令的排序,该排序中每个 CPU 要执行指令的顺序得以保持,且实际的 CPU 执行结果与该指令排序的执行结果一致,则称该次执行达到了顺序一致性。
==越是宽松的一致性模型,能容纳的事件排列可能性就越多;反之越严格则越少。==
顺序一致性有两个要求:
- 任何一次读都能读到某个数据的最近一次写的数据。
- 系统的所有进程的顺序一致,而且是合理的。即不需要和全局时钟下的顺序一致,错的话一起错,对的话一起对。
例子1

图中 W(X, 1) 代表将 1 写入变量 X;R(X, 1) 代表读取变量 X,值为 1;横轴代表时间;矩形的长短代表指令持续的时间长短,所以上图其实表示的是多核 CPU 的一次执行结果。
我们找到了指令的一个排序,排序中各个 CPU 的指令顺序得以保持(如 C: R(X, 1) 在 C: R(X, 2) 之前),这个排序的执行结果与 CPU 分开执行的结果一致,因此该 CPU 的执行是满足顺序一致性的。
注意到==顺序一致性关心的是 CPU 内部执行指令的顺序,而不关心 CPU 之间的相对顺序。==
例子2

Write(x, 4):写入x=4
Read(x, 0):读出x=0
1)图a是满足顺序一致性,但是不满足强一致性的。
原因在于,从全局时钟的观点来看,P2进程对变量X的读操作在P1进程对变量X的写操作之后,然而读出来的却是旧的数据。
但是这个图却是满足顺序一致性的,因为两个进程P1,P2的一致性并没有冲突。从这两个进程的角度来看,顺序应该是这样的:
Write(y,2) , Read(x,0) , Write(x,4), Read(y,2),
每个进程内部的读写顺序都是合理的,但是这个顺序与全局时钟下看到的顺序并不一样。
2)图b满足强一致性,因为每个读操作都读到了该变量的最新写的结果,同时两个进程看到的操作顺序与全局时钟的顺序一样,都是
Write(y,2) , Read(x,4) , Write(x,4), Read(y,2)。
3)图c不满足顺序一致性,当然也就不满足强一致性了。
因为从进程P1的角度看,它对变量Y的读操作返回了结果0。
那么就是说,P1进程的对变量Y的读操作在P2进程对变量Y的写操作之前,这意味着它认为的顺序是这样的:
write(x,4) , Read(y,0) , Write(y,2), Read(x,0),
显然这个顺序又是不能被满足的,因为最后一个对变量x的读操作读出来也是旧的数据。因此这个顺序是有冲突的,不满足顺序一致性。
https://blog.csdn.net/chao2016/article/details/81149674
例子3
一条朋友圈下面有多个人发表评论,朋友圈这个分布式系统,有两种客户端:发朋友圈的客户端负责写入数据,读朋友圈的客户端负责读取数据,当然很多时候同一个客户端既能读也能写。
接下来的问题是:
- 这些看朋友圈的人,是否能看到全局一致的数据?即所有人看到的朋友圈都是同一个顺序排列的?
显然,有很多时候,即便是在看同一个朋友圈下的评论回复,不同的人看到也不尽然都是同一个顺序的,所以以上的答案是否定的。那么就引入了下一个问题:
- 如果不同的人看到的朋友圈(包括评论)顺序各有不同,这些顺序又该遵守怎样的规则才是合理的?
一条朋友圈下面有多个人发表评论,可以认为这是一个二维的数据:
- 进程(也就是发表评论的人)是一个维度。
- 时间又是另一个维度,即这些评论出现的先后顺序。
但是在阅读这些评论的读者看来,需要将这一份二维的数据,去除掉不同进程这个维度,压平到只有本进程时间线这一个单一维度上面来,如图所示:
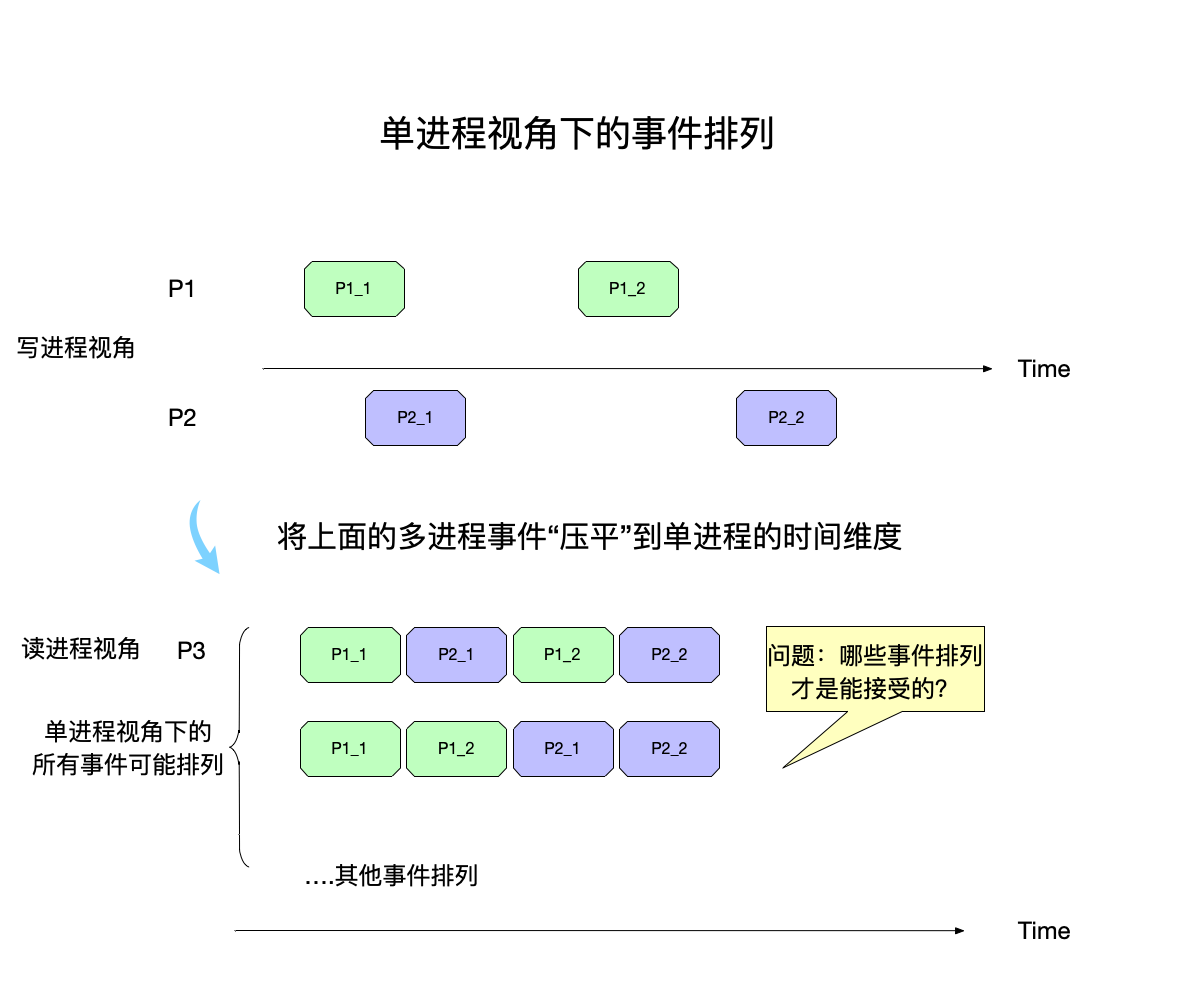
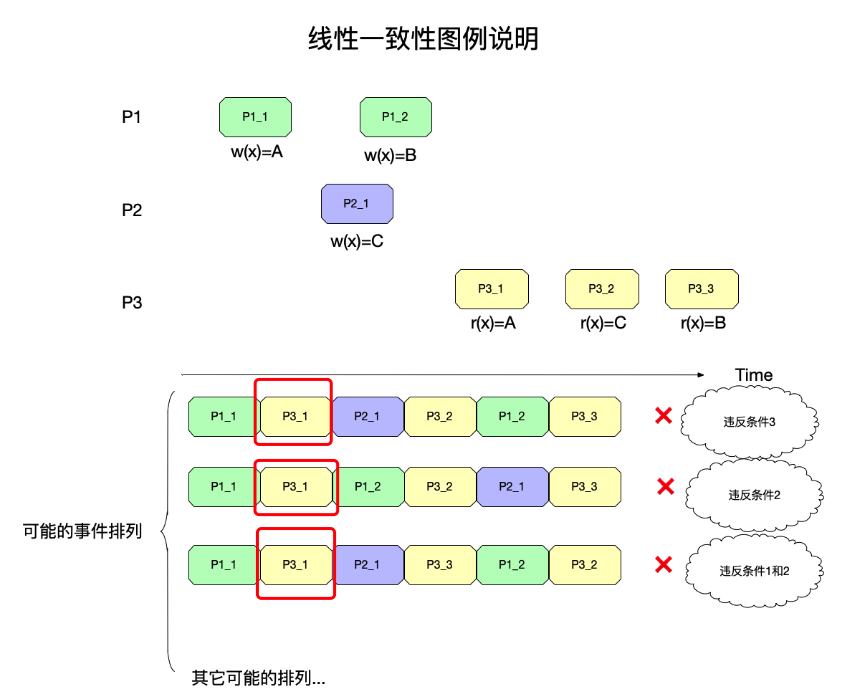
在上图中,在读进程P3的视角看来,两个写进程的事件,需要压平到本进程的时间线上进行排列,可以看到这些事件在压平之后有多种排列的可能性。
将多个写进程的事件进行排列,放到单进程的时间线上,这是一个排列组合问题,如果所有的写进程事件加起来一共有n个,那么这些事件的所有排列组合就是n!。比如事件a、b、c,不同的排列一共有这些:
{(a,b,c),(a,c,b),(b,a,c),(b,c,a),(c,a,b),(c,b,a)}
一致性模型就是要回答:在所有的这些可能存在的事件排列组合中,按照要求的一致性严格程度,哪些是可以接受的,哪些不可能出现?
后面的讲述将看到:==越是宽松的一致性模型,能容纳的事件排列可能性就越多;反之越严格则越少。==
举一个违反这个条件的反例,如下图所示:
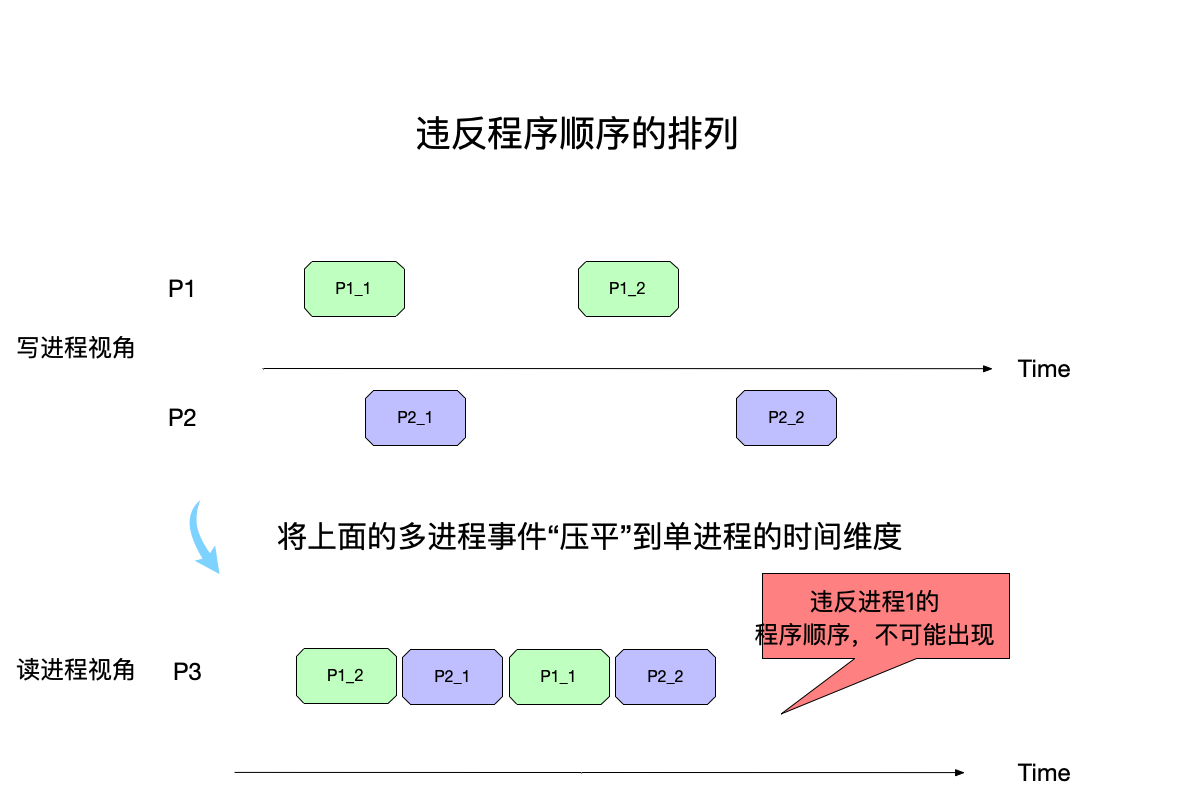
上图中:
- 进程p1视角下:程序的执行顺序是先执行 P_1,再执行 P_2。
- 但是到了P3视角下重排事件之后,P1_2出现在了事件P1_1前面,这是不允许出现的,因为违反了原进程P1程序顺序了。
但是,仅靠条件1还不足以满足顺序一致性,于是还有条件2:
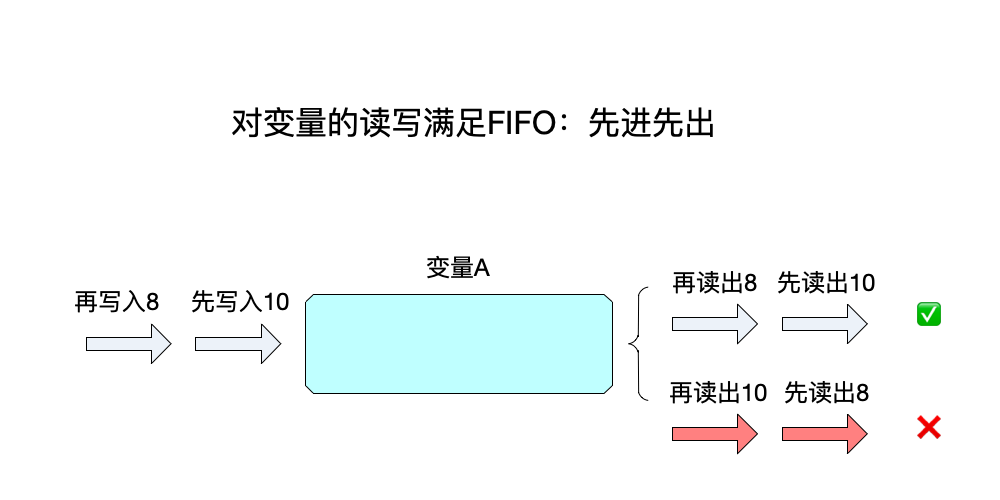
- 条件2:对变量的读写要表现得像FIFO一样先入先出,即
每次读到的都是最近写入的数据。
特殊例子
在顺序一致性模型下,第一个排列和第二个排列都被认为是正确的。
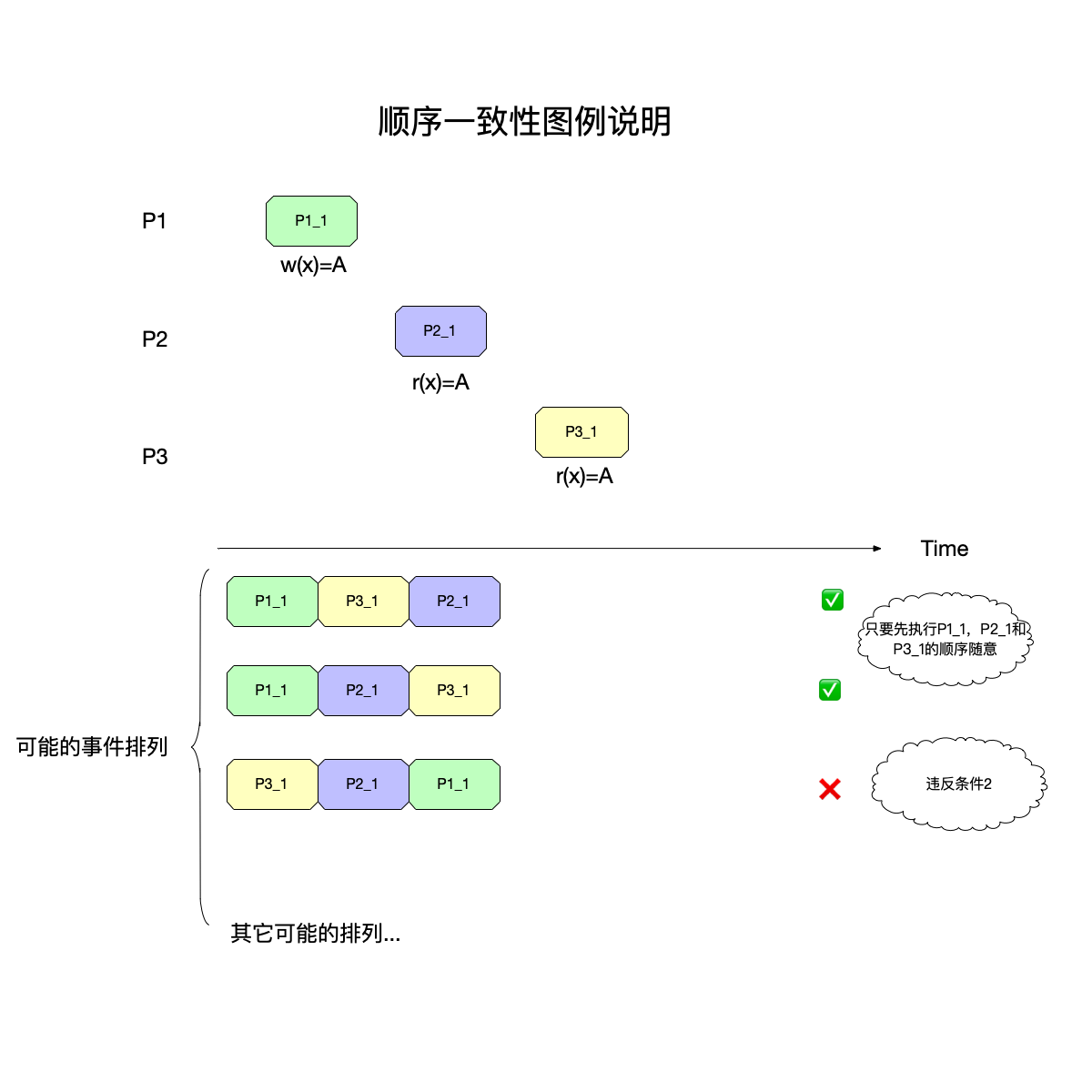
p1_1 , p2_1 , p3_1 和 p1_1 , p3_1 , p2_1 都被认为是对的,因为没有违反两个条件
- 任何一次读都能读到某个数据的最近一次写的数据。
- 系统的所有进程的顺序一致,而且是合理的。即不需要和全局时钟下的顺序一致,错的话一起错,对的话一起对。
第三个排列违反了条件2
顺序一致性在满足了条件1、2之后,对不同进程的事件之间的顺序没有硬性的要求,即便在感官直觉上某事件应该发生得更早,但是只要没有违反这两个条件就可以认为是满足顺序一致性模型的。
于是就出现了更严格的线性一致性,它基于顺序一致性的条件,对事件的先后顺序做了更严格的要求。
https://www.codedump.info/post/20220710-weekly-22
顺序一致性难吗?
难,现代的多核 CPU 依然达不到顺序一致性。
我们知道 CPU 执行的主要瓶颈其实是在与内存交互,工程师为了让 CPU 能高速执行,在 CPU 内部使用了多级缓存。它的存在,使得即使 CPU 内部顺序执行指令,指令的结果也可能不满足顺序一致性:

上图中 (n) 代表数据的读写步骤。如果 CPU 如上图执行,则得到的结果不满足顺序一致性。
另外 CPU 执行时会乱序执行指令。例如在一些情况下 CPU 会将数据写入的指令提前执行,因为写入内存是很耗时的。同样的,编译器在编译代码时也会重排代码中的指令的顺序,以提升整体的性能。
难以想象,没有了顺序一致性的保证,程序居然还能正确执行。其实,现代硬件体系遵循的其实是:
sequential consistency for data race free programs
即如果程序没有数据竞争,则 CPU 可以保证顺序一致性,而如果遇到数据竞争,就需要程序里手工使用一些数据同步的机制(如锁)。
工程领域总是伴随着各种权衡(trade-off),显然保证顺序一致性对 CPU 的性能优化有太多的阻碍,而 CPU 的高性能又是我们所追求的,两害相权取其轻。
https://lotabout.me/2019/QQA-What-is-Sequential-Consistency/
线性一致性-背景知识
分布式系统可以抽象成几个部分:
- Client
- Server
- Events
- Invocation
- Response
- Operations
- Read
- Write
一个分布式系统通常有两种角色,Client 和 Server。Client 通过发起请求来获取 Server 的服务。一次完整请求由两个事件组成,Invocation(以下简称 Inv)和 Response(以下简称 Resp)。一个请求中包含一个 Operation,有两种类型 Read 和 Write,最终会在 Server 上执行。
说了一堆不明所以的概念,现在来看如何用这些表示分布式系统的行为。
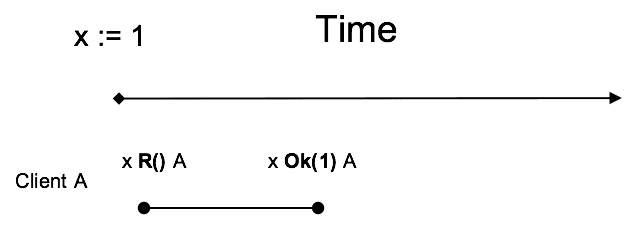
上图展示了 Client A 的一个请求从发起到结束的过程。变量 x 的初始值是 1,“x R() A” 是一个事件 Inv 意思是 A 发起了读请求,相应的 “x OK(1) A” 就是事件 Resp,意思是 A 读到了 x 且值为 1,Server 执行读操作(Operation)。
线性一致性
最强的一致性要求
它基于顺序一致性的条件,对事件的先后顺序做了更严格的要求。
怎样才能达到线性一致?这就要求 Server 在执行 Operations 时需要满足以下三点:
- 瞬间完成(或者原子性)
- 发生在 Inv 和 Resp 两个事件之间
- 反映出“最新”的值
举一个例子,用以解释上面三点。
另一种说法
- 不能打乱单进程的程序顺序,同一个进程里的事件先后顺序要得到保留。
- 不同进程的事件,如果在时间上不重叠,即不是并发事件,那么要求这个先后顺序在重排之后保持一致。
- 每次读出来的都是最新的值,而且一旦形成了一个排列,要求系统中所有进程都是同样的一个排列。
例子1
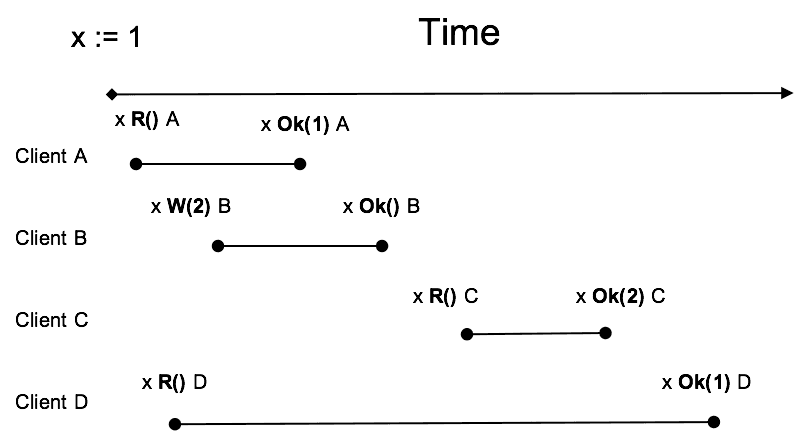
先下结论,上图表示的行为满足线性一致。
对于同一个对象 x,其初始值为 1,客户端 ABCD 并发地进行了请求,按照真实时间(real-time)顺序,各个事件的发生顺序如上图所示。
对于任意一次请求都需要一段时间才能完成,例如 A,“x R() A” 到 “x Ok(1) A” 之间的那条线段就代表那次请求花费的时间,而请求中的读操作在 Server 上的执行时间是很短的,相对于整个请求可以认为瞬间,读操作表示为点,并且在该线段上。
线性一致性中没有规定读操作发生的时刻,也就说该点可以在线段上的任意位置,可以在中点,也可以在最后,当然在最开始也无妨。
下面说第三点。
反映出“最新”的值?我觉得三点中最难理解就是它了。
先不急于对“最新”下定义,来看看上图中 x 所有可能的值,显然只有 1 和 2。
四个次请求中只有 B 进行了写请求,改变了 x 的值,我们从 B 着手分析,明确 x 在各个时刻的值。
由于不能确定 B 的 W(写操作)在哪个时刻发生,能确定的只有一个区间,因此可以引入上下限的概念。
对于 x=1,它的上下限为开始到事件“x W(2) B”,在这个范围内所有的读操作必定读到 1。对于 x=2,它的上下限为 事件“x Ok() B” 到结束,在这个范围内所有的读操作必定读到 2。
那么“x W(2) B”到“x Ok() B”这段范围,x 的值是什么?1 或者 2。由此可以将 x 分为三个阶段,各阶段"最新"的值如下图所示:
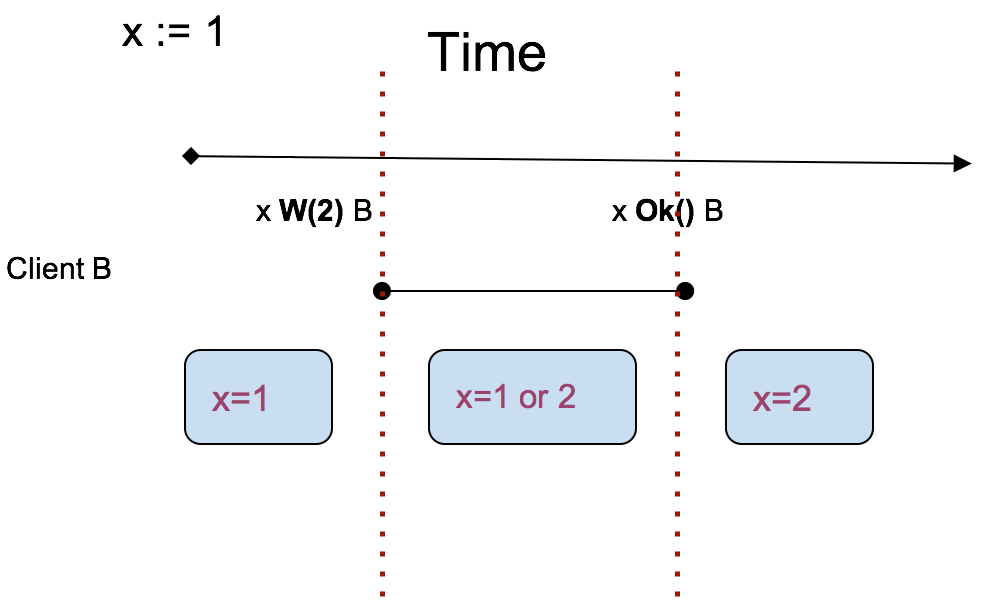
清楚了 x 的变化后理解例子中 A C D 的读到结果就很容易了。
最后返回的 D 读到了 1,看起来是 “stale read”,其实并不是,它仍满足线性一致性。
==D 请求横跨了三个阶段,而读可能发生在任意时刻,所以 1 或 2 都行。==同理,A 读到的值也可以是 2。C 就不太一样了,C 只有读到了 2 才能满足线性一致。
因为 “x R() C” 发生在 “x Ok() B” 之后(happen before ),可以推出 R 发生在 W 之后,那么 R 一定得读到 W 完成之后的结果:2。
一句话概括:在分布式系统上实现寄存器语义。
一旦我们将一个变量设置为某个值,例如 a,读取时就会返回 a,直到我们再次对值做了变更。读取一个变量返回最近写入的值。我们称这种系统为有单一值的变量 —— 一个寄存器。
https://blog.csdn.net/u013200380/article/details/113050620
例子2
如果是线性一致性
下图里只有 p1_1 , p2_1, p3_1是满足线性一致性的排列了
这还是最开始解释顺序一致性模型的图,但是在线性一致性的条件下,找不到能够满足条件的排列了。
这是因为:
- 事件 P2_1 和 P1_2 都在事件 P1_1 之后,这个顺序需要得到保持。
- 而事件 P3_1 在事件 P2_1 和 P1_2 之后,这个顺序也需要得到保持。
- 如果保持了前面两个顺序,那么 P3_1 执行的时候,必然读不出来A,而应该是B或者C(即 P2_1 或者 P1_2的执行结果)。
顺序一致性和线性一致性总结
可以看到,如果满足线性一致性,就一定满足顺序一致性,因为后者的条件是前者的真子集。
除了满足这些条件以外,这两个一致性还有一个要求:==系统中所有进程的顺序是一致的,即如果系统中的进程A按照要求使用了某一种排序,即便有其他排序的可能性存在,系统中的其他进程也必须使用这种排序,系统中只能用一种满足要求的排序。==
这个要求,使得满足顺序和线性一致性的系统,对外看起来“表现得像只有一个副本”一样。
但因果一致性则与此不同:只要满足因果一致性的条件,即便不同进程的事件排列不一致也没有关系。
关联问题:线性一致性和序列化(Linearizability and Serializability)
Serializability: 数据库领域的ACID中的I。 数据库的四种隔离级别,由弱到强分别是Read Uncommitted,Read Committed(RC),Repeatable Read(RR)和Serializable。
Serializable的含义是:对并发事务包含的操作进行调度后的结果和某种把这些事务一个接一个的执行之后的结果一样。最简单的一种调度实现就是真的把所有的事务进行排队,一个个的执行,显然这满足Serializability,问题就是性能。可以看出Serializability是与数据库事务相关的一个概念,一个事务包含多个读,写操作,这些操作由涉及到多个数据对象。
- Linearizability: 针对单个操作,单个数据对象而说的。属于CAP中C这个范畴。一个数据被更新后,能够立马被后续的读操作读到。
- Strict Serializability: 同时满足Serializability和Linearizability。
==例子:==
两个事务T1,T2,T1先开始,更新数据对象o,T1提交。接着T2开始,读数据对象o,提交。以下两种调度:
- T1,T2,满足Serializability,也满足Linearizability。
- T2,T1,满足Serializability,不满足Linearizability,因为T1之前更新的数据T2读不到。
因果一致性
因果一致性,属于弱一致性,因为在Causal consistency中,==只对有因果关系的事件有顺序要求==。
没有因果一致性时会发生如下情形:
- 夏侯铁柱在朋友圈发表状态“我戒指丢了”
- 夏侯铁柱在同一条状态下评论“我找到啦”
- 诸葛建国在同一条状态下评论“太棒了”
- 远在美国的键盘侠看到“我戒指丢了”“太棒了”,开始喷诸葛建国
- 远在美国的键盘侠看到“我戒指丢了”“我找到啦”“太棒了”,意识到喷错人了
所以很多系统采用因果一致性系统来避免这种问题,例如微信的朋友圈就采用了因果一致性,可以参考:https://www.useit.com.cn/thread-10587-1-1.html
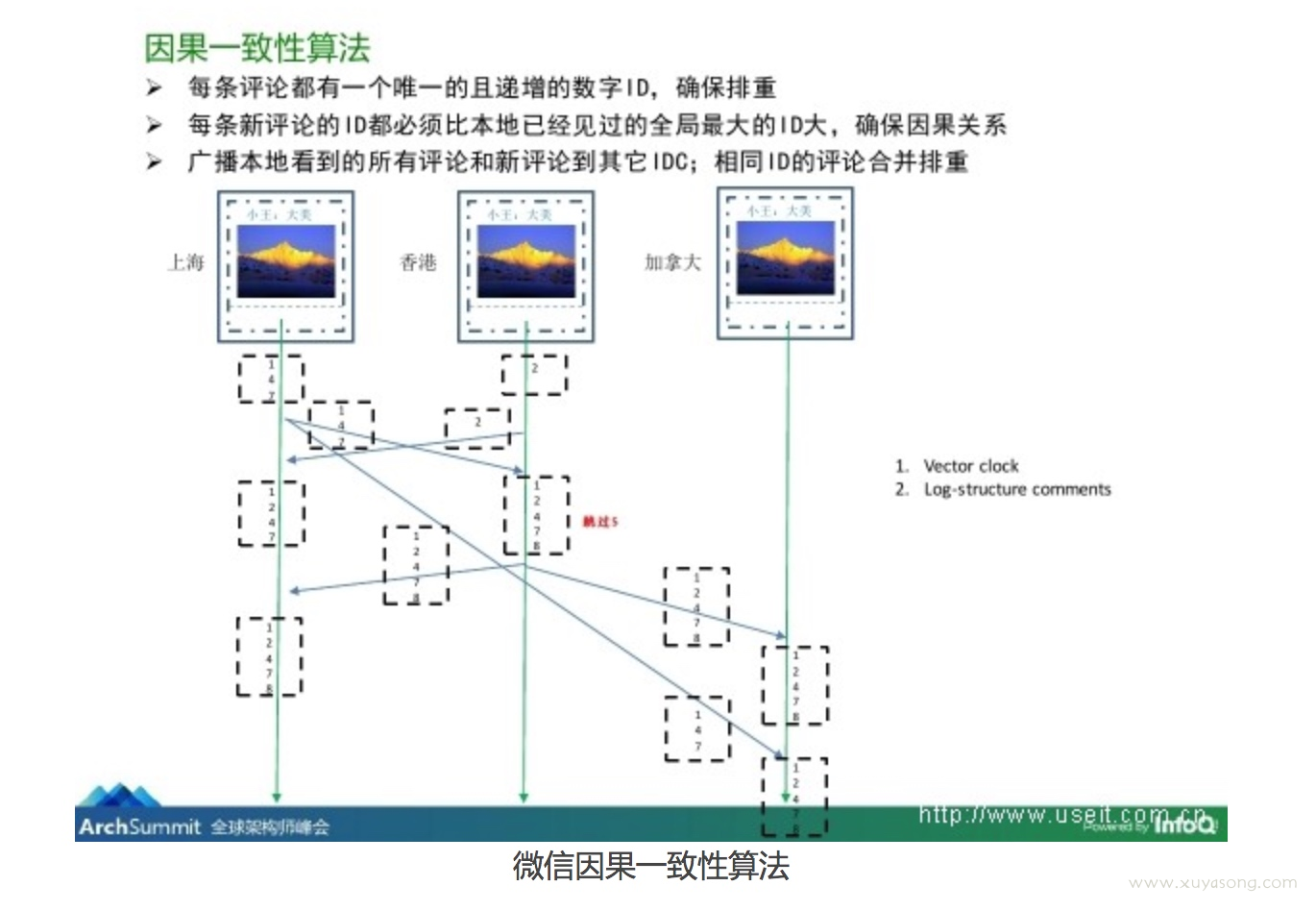
例子
以评论朋友圈这个行为来解释因果一致性再合适不过:
- 评论另一个用户的评论:相当于进程给另一个进程发消息,肯定要求满足
happen-before关系,即先有了评论,才能针对这个评论发表评论。 - 同一个用户的评论:相当于同一个进程的事件,也是必须满足
happen-before关系才行。
以下图为例:
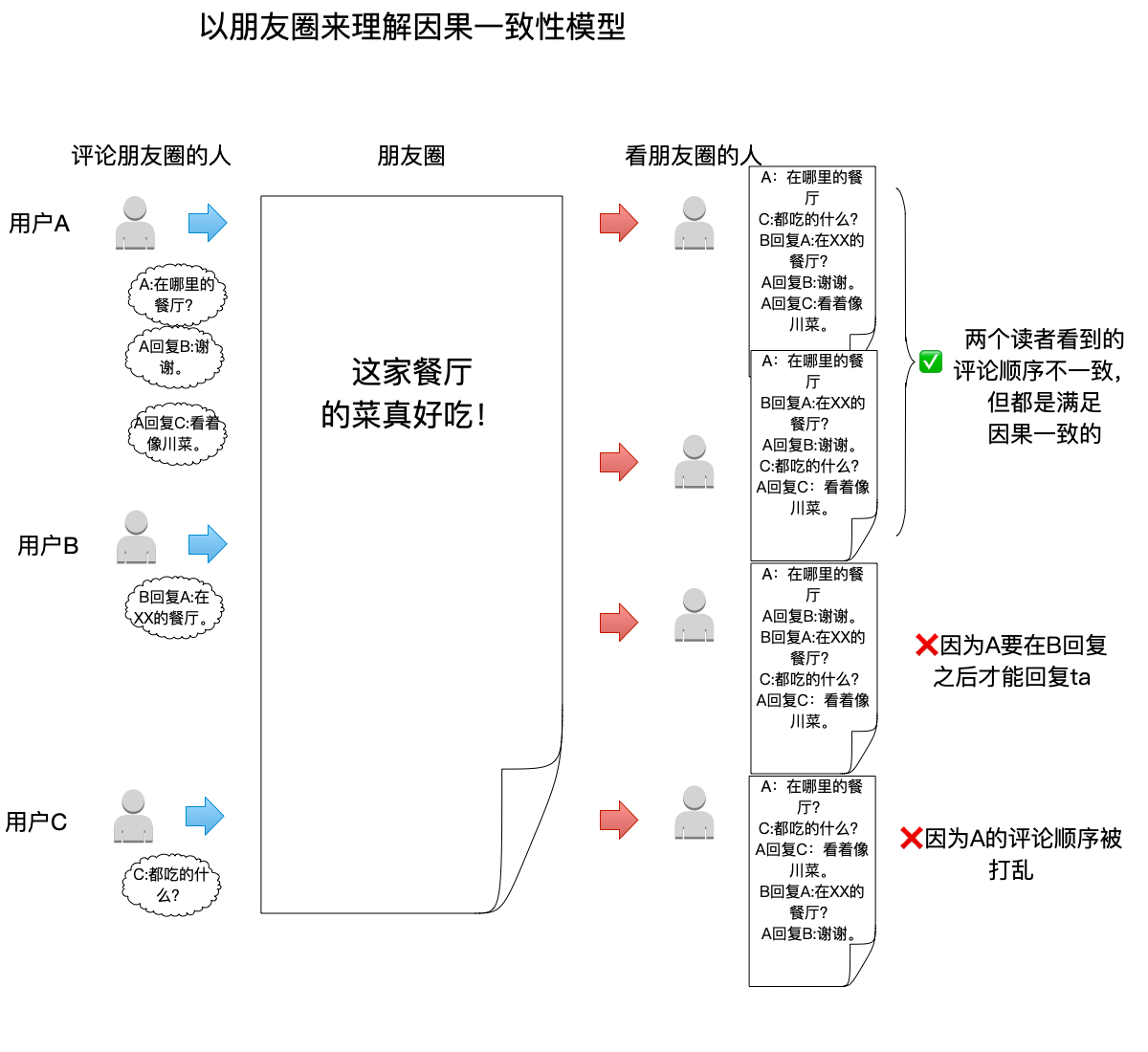
一共有4个朋友圈的读者,它们看到的评论顺序都各不一样:
- 最上面的两个读者,读到的顺序都满足因果一致性,因此即便是不一样的顺序也是正确的。
- 最下面的两个读者,顺序都不满足因果一致性:
- A回复B这个事件出现在了B回复A之前,不符合多进程之间的
happen-before关系。 - A回复C这个事件在进程A中应该在A回复B之前,不符合同一进程的事件之间的先后顺序。
- A回复B这个事件出现在了B回复A之前,不符合多进程之间的
最终一致性
最终一致性这个词大家听到的次数应该是最多的,也是弱一致性,不过因为大多数场景下用户可以接受,应用也就比较广泛。
理念:不保证在任意时刻任意节点上的同一份数据都是相同的,但是随着时间的迁移,不同节点上的同一份数据总是在向趋同的方向变化。
简单说,就是在一段时间后,节点间的数据会最终达到一致状态。
redis主备、mongoDB、乃至mysql热备都可以算是最终一致性,甚至如果我记录操作日志,然后在副本故障了100天之后手动在副本上执行日志以达成一致,也算是符合最终一致性的定义。有人说最终一致性就是没有一致性,因为没人可以知道什么时候算是最终。
最终一致其实分支很多,以下都是他的变种:
- Causal consistency(因果一致性)
- Read-your-writes consistency (读己所写一致性)
- Session consistency (会话一致性)
- Monotonic read consistency (单调读一致性)
- Monotonic write consistency (单调写一致性)
BASE理论中的 E,就是Eventual consistency最终一致
总结
-
在分布式系统中,多个进程组合在一起协调工作,产生多个事件,事件之间可以有多种排列的可能性。
-
一致性模型本质上要回答这个问题:按照该一致性模型定义,怎样的事件发生顺序的排列才符合要求?
-
顺序一致性和线性一致性都意图让系统中所有进程
看起来有统一的全局事件顺序,但是两者的要求不同,顺序一致性:- 条件1:每个进程的执行顺序要和该进程的程序执行顺序保持一致。
- 条件2:对变量的读写要表现得像FIFO一样先入先出,即每次读到的都是最近写入的数据。
只要满足这两个条件,顺序一致性对事件之间的先后顺序并没有硬性要求,而线性一致性在此基础上多了条件3:
- 条件3:不同进程的事件,如果在时间上不重叠,即不是并发事件,那么要求这个先后顺序在重排之后保持一致。
-
因果一致性是更弱的一致性,只要满足
happen-before关系即可。由于happen-before关系实际上是由Lamport时钟定义的,这是一种逻辑时钟,所以不同的读者看到的先后顺序可能会有点反直觉,但是只要满足happen-before关系就是正确的。
大佬的总结链接:https://www.codedump.info/post/20220710-weekly-22/#%E6%80%BB%E7%BB%93