你项目里的Redis和DB是如何保持一致性的?
首先,如果要实现两者在同一时间上的完全的一致,完全的同步是不可能的。
如果业务上对数据不一致零容忍,就使用分布式锁。
从理论上来说,给缓存设置过期时间,是可以保证最终一致性的解决方案。
这种方案下,我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可,也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存
现有策略总是或多或少都有些缺陷的,能说清楚各种策略哪些地方可能会导致不一致就行了
接下来讨论的思路不依赖于给缓存设置过期时间这个方案,并且尽可能的实现缓存与数据库的一致性。
我们讨论三种更新策略:
- 先更新数据库,再更新缓存
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
先更新数据库,再更新缓存
结论:不推荐
如果同时有请求A和请求B进行更新操作,那么会出现
(1)线程A更新了数据库
(2)线程B更新了数据库
(3)线程B更新了缓存
(4)线程A更新了缓存
这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据,因此不考虑。
先删除缓存,再更新数据库
该方案会导致不一致的原因是。同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形:
(1)请求A进行写操作,删除缓存
(2)请求B查询发现缓存不存在
(3)请求B去数据库查询得到旧值
(4)请求B将旧值写入缓存
(5)请求A将新值写入数据库
上述情况就会导致不一致的情形出现。而且,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
延时双删策略
先淘汰缓存
再写数据库(这两步和原来一样)
休眠一段时间,再次淘汰缓存
这么做,可以将这一段时间内所造成的缓存脏数据,再次删除。
下次再有读取请求时,会访问缓存,缓存没有,去数据库拿到最新的,同时更新缓存
如果db、cache 不是单机而是主从配置怎么办
在这种情况下,造成数据不一致的原因如下,还是两个请求,一个请求A进行更新操作,另一个请求B进行查询操作。
(1)请求A进行写操作,删除缓存
(2)请求A将数据写入数据库了,
(3)请求B查询缓存发现,缓存没有值
(4)请求B去从库查询,这时,还没有完成主从同步,因此查询到的是旧值
(5)请求B将旧值写入缓存
(6)数据库完成主从同步,从库变为新值
还是使用双删延时策略。只是,睡眠时间修改为在主从同步的延时时间基础上,加几百ms。
多加的时间是为了让db、cache 内部同步。
采用这种同步淘汰策略,吞吐量降低怎么办?
那就将第二次删除作为异步的。自己起一个线程,异步删除。这样,写的请求就不用沉睡一段时间后了,再返回。这么做,加大吞吐量。
第二次删除,如果删除失败怎么办?
第二次删除失败,就会出现如下情形。还是有两个请求,一个请求A进行更新操作,另一个请求B进行查询操作,为了方便,假设是单库:
(1)请求A进行写操作,删除缓存
(2)请求B查询发现缓存不存在
(3)请求B去数据库查询得到旧值
(4)请求B将旧值写入缓存
(5)请求A将新值写入数据库
(6)请求A试图去删除请求B写入对缓存值,结果失败了。
ok,这也就是说。如果第二次删除缓存失败,会再次出现缓存和数据库不一致的问题。
如何解决异步删除失败
先更新db,再删除cache
先更新数据库,再删除缓存
Cache-Aside pattern
老外提出了一个缓存更新套路,名为《Cache-Aside pattern》。其中就指出
- 失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
另外,知名社交网站facebook也在论文《Scaling Memcache at Facebook》中提出,他们用的也是先更新数据库,再删缓存的策略。
假设这会有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生
(1)缓存刚好失效
(2)请求A查询数据库,得一个旧值
(3)请求B将新值写入数据库
(4)请求B删除缓存
(5)请求A将查到的旧值写入缓存
ok,如果发生上述情况,确实是会发生脏数据。
==发生上述情况有一个先天性条件==,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。
可是,大家想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少),因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。
假设,有人非要抬杠,有强迫症,一定要解决怎么办?
如何解决上述并发问题?
首先,给缓存设有效时间是一种方案。其次,采用策略(2)里给出的异步延时删除策略,保证读请求完成以后,再进行删除操作。
还有其他造成不一致的原因么?
有的,这也是 先删缓存后更新数据库 和 先更新数据库后删缓存都存在的一个问题,如果删缓存失败了怎么办,那不是会有不一致的情况出现么。
比如一个写数据请求,然后写入数据库了,删缓存失败了,这会就出现不一致的情况了。
如何解决最后的问题?
提供一个保障的重试机制即可,这里给出两套方案。
方案一:消息队列重试
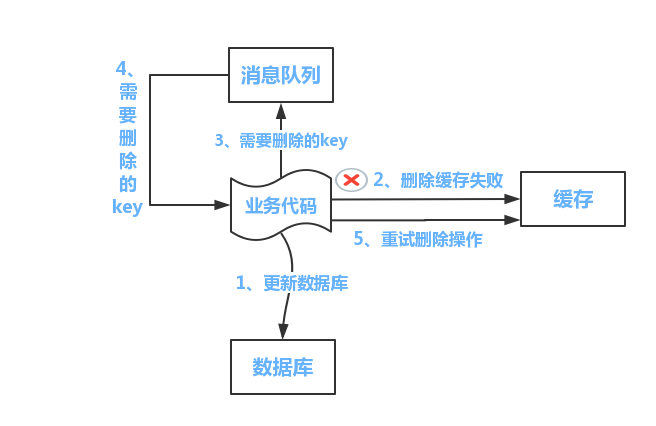
流程如下所示
(1)更新数据库数据;
(2)缓存因为种种问题删除失败
(3)将需要删除的key发送至消息队列
(4)自己消费消息,获得需要删除的key
(5)继续重试删除操作,直到成功
然而,该方案有一个缺点,对业务线代码造成大量的侵入。于是有了方案二,在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
方案二:binlog订阅机制
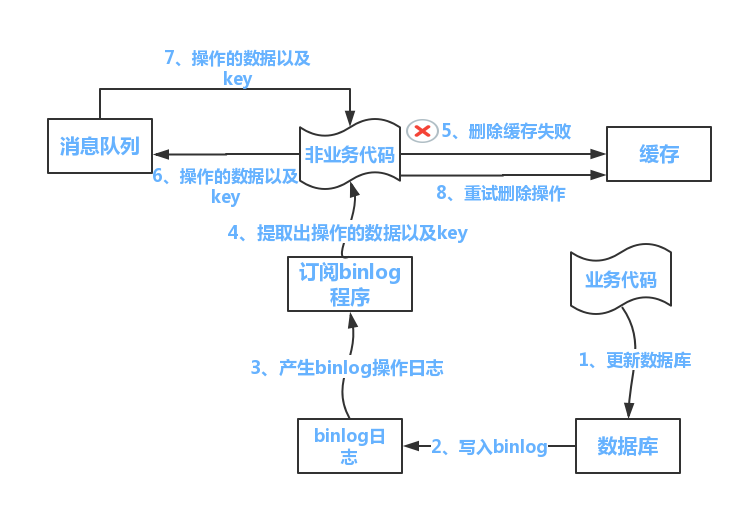
流程如下图所示:
(1)更新数据库数据
(2)数据库会将操作信息写入binlog日志当中
(3)订阅程序提取出所需要的数据以及key
(4)另起一段非业务代码,获得该信息
(5)尝试删除缓存操作,发现删除失败
(6)将这些信息发送至消息队列
(7)重新从消息队列中获得该数据,重试操作。
**备注说明:**上述的订阅binlog程序在mysql中有现成的中间件叫canal,可以完成订阅binlog日志的功能。至于oracle中,博主目前不知道有没有现成中间件可以使用。
解决方案
分别处理
针对某些对数据一致性要求不是特别高的情况下,可以将这些数据放入Redis,请求来了直接查询Redis,例如近期回复、历史排名这种实时性不强的业务。
而针对那些强实时性的业务,例如虚拟货币、物品购买件数等等,则直接穿透Redis至MySQL上,等到MySQL上写入成功,再同步更新到Redis上去。这样既可以起到Redis的分流大量查询请求的作用,又保证了关键数据的一致性。
高并发情况下
此时如果写入请求较多,则直接写入Redis中去,然后间隔一段时间,批量将所有的写入请求,刷新到MySQL中去;如果此时写入请求不多,则可以在每次写入Redis,都立刻将该命令同步至MySQL中去。这两种方法有利有弊,需要根据不同的场景来权衡。
基于订阅binlog的同步机制
阿里巴巴的一款开源框架canal,提供了一种发布/ 订阅模式的同步机制,通过该框架我们可以对MySQL的binlog进行订阅,这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。值得注意的是,binlog需要手动打开,并且不会记录关于MySQL查询的命令和操作。
分布式系统里要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率
缓存系统适用的场景就是非强一致性的场景,所以它属于CAP中的AP,BASE理论。
异构数据库本来就没办法强一致,只是尽可能减少时间窗口,达到最终一致性。
还有别忘了设置过期时间,这是个兜底方案
陈浩《缓存更新的套路》
Reference
https://coolshell.cn/articles/17416.html
https://www.cnblogs.com/rjzheng/p/9041659.html
https://blog.csdn.net/qq_30683329/article/details/80543178
https://juejin.cn/post/6964531365643550751